简短答案:
先明确作品目标并建立角色和视觉资产,再完成分镜、镜头与关键帧;随后使用 Seedance 2.0、Kling 3O 等视频模型推进镜头,使用 Fish Audio TTS 等声音模型制作对白与旁白,最后通过审阅和版本管理完成短片、动画、TVC 或电影镜头。
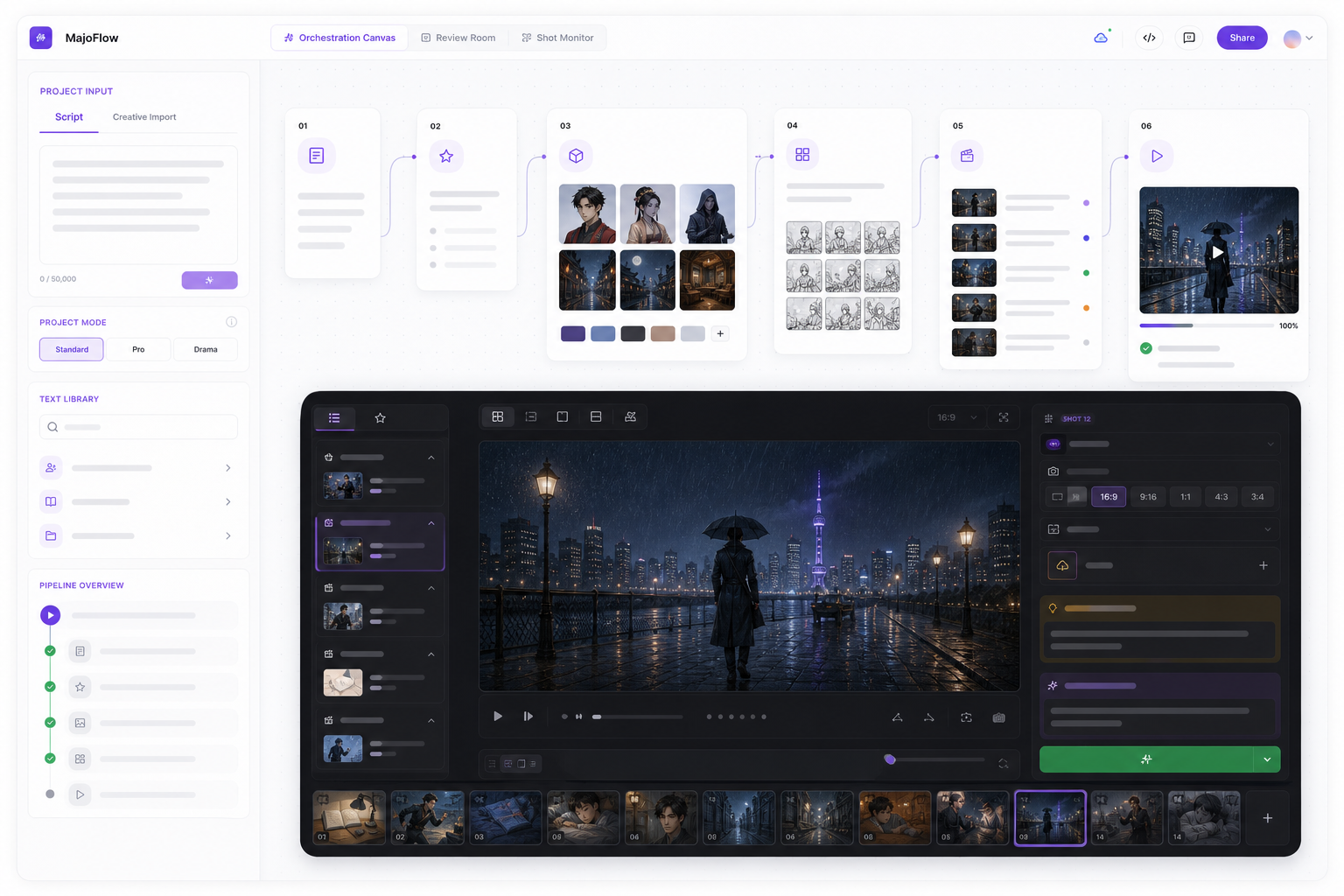
从创意到成片的 AI 视频生产流程
| 阶段 | 核心任务 | 可使用的能力与模型 |
|---|---|---|
| 创意与脚本 | 明确概念、受众、时长、内容结构和镜头目标 | 创意卡片、文本模型、Agent |
| 设计与角色 | 制作角色、场景、道具、风格和关键视觉 | Nano Banana / NANObanana、Nano Banana Pro、GPT-Image-2 |
| 分镜与预演 | 规划构图、动作、机位、运动、节奏和镜头关系 | CanvasMAX、编排画布、MajoSpace |
| 动画与视频 | 生成镜头、动作、参考视频和连续片段 | Seedance 2.0、Kling 3O(Kling 3 Omni / kling3OMNI) |
| 声音 | 制作对白、旁白、角色声音和声音参考 | Fish Audio TTS、Gemini TTS |
| 审阅与交付 | 比较版本、修正问题、确认镜头并输出 | 视频审阅、任务队列、资产与版本记录 |
同一套工作流可以完成哪些作品
不同项目的交付规格和制作深度不同,但底层都需要设计、资产、镜头、视频、声音和版本管理。MajoFlow 将这些内容放在同一个项目中,让创作者按作品要求调整流程。
- 视觉设计与角色:探索风格、角色造型、场景、道具和关键视觉。
- AI 动画:围绕角色、关键帧、动作和声音组织连续片段。
- AI 短片与短剧:从脚本、分集、故事板和分镜推进到视频镜头。
- TVC 与广告视频:管理创意方向、产品视觉、镜头版本和交付审阅。
- 电影与长内容:用于概念设计、预演、资产、镜头和生成素材的持续生产;最终交付深度取决于项目规格与后期流程。
为什么不能只依赖一个视频模型
视频模型负责生成镜头,但短片和动画还需要图像模型完成设计和关键帧,需要文本模型处理脚本和镜头描述,需要 TTS 与声音能力完成对白和旁白,也需要画布、分镜、审阅和版本记录来管理过程。
MajoFlow 将模型能力放进具体任务中。创作者可以使用 Nano Banana 或 GPT-Image-2 处理视觉设计与参考帧,再将结果交给 Seedance 2.0 或 Kling 3O 生成视频,并使用 Fish Audio TTS 处理角色声音。
MajoFlow 如何组织 AI 短片与动画
- 创意卡片:发展概念、角色、故事、脚本和镜头描述。
- CanvasMAX:在 AI 画布中组织设计、参考、关键帧、视频片段、声音和生成迭代。
- 编排画布:按剧本、资产、故事板、分镜、视频和审阅步骤推进项目。
- MajoSpace:在生成前检查空间、构图、机位、镜头和角色站位。
- 资产与任务系统:保存角色、参考、成功结果和生成记录,并管理批量任务。
常见问题
AI 短片可以只用一个视频模型完成吗?
可以生成部分镜头,但完整作品通常还需要设计、角色资产、分镜、关键帧、声音、审阅和版本管理。多种模型围绕同一个项目协作会更可靠。
MajoFlow 可以做设计和角色吗?
可以。设计和角色是视觉生产流程的上游资产,可以在 CanvasMAX 中使用图像模型进行生成、编辑、比较和复用,再继续进入分镜、动画和视频。
MajoFlow 是否只适合短片?
不是。MajoFlow 可用于设计、角色、动画、AI 短片、短剧、TVC 和电影相关的概念、预演、镜头与生成素材生产。具体交付方式取决于项目规格。